前言
在数字化浪潮的推动下,电商平台已经彻底改变了我们的购物方式。从简单的在线交易到复杂的用户交互,电商平台积累了海量的用户数据。这些数据,如同隐藏在深海中的宝藏,等待着被发掘和利用。通过分析用户的浏览、搜索、购买等行为,商家可以更准确地理解用户需求,提供个性化的推荐和服务。这不仅能够提升用户的购物体验,还能增加用户粘性和忠诚度。此外,电商平台数据分析在库存管理、价格策略制定、竞争分析、风险管理等方面也发挥着重要作用。它能够帮助商家优化库存,制定合理的定价策略,了解竞争对手的市场表现,以及及时发现并应对潜在的风险。
在本文中,我们将深入探讨如何构建出既高效的爬虫,为你的电商业务提供强大的支持。
亮数据数据获取工具![]() https://www.bright.cn/proxy-types?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_yingjie
https://www.bright.cn/proxy-types?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_yingjie
利用代理IP爬取当当网
网站分析
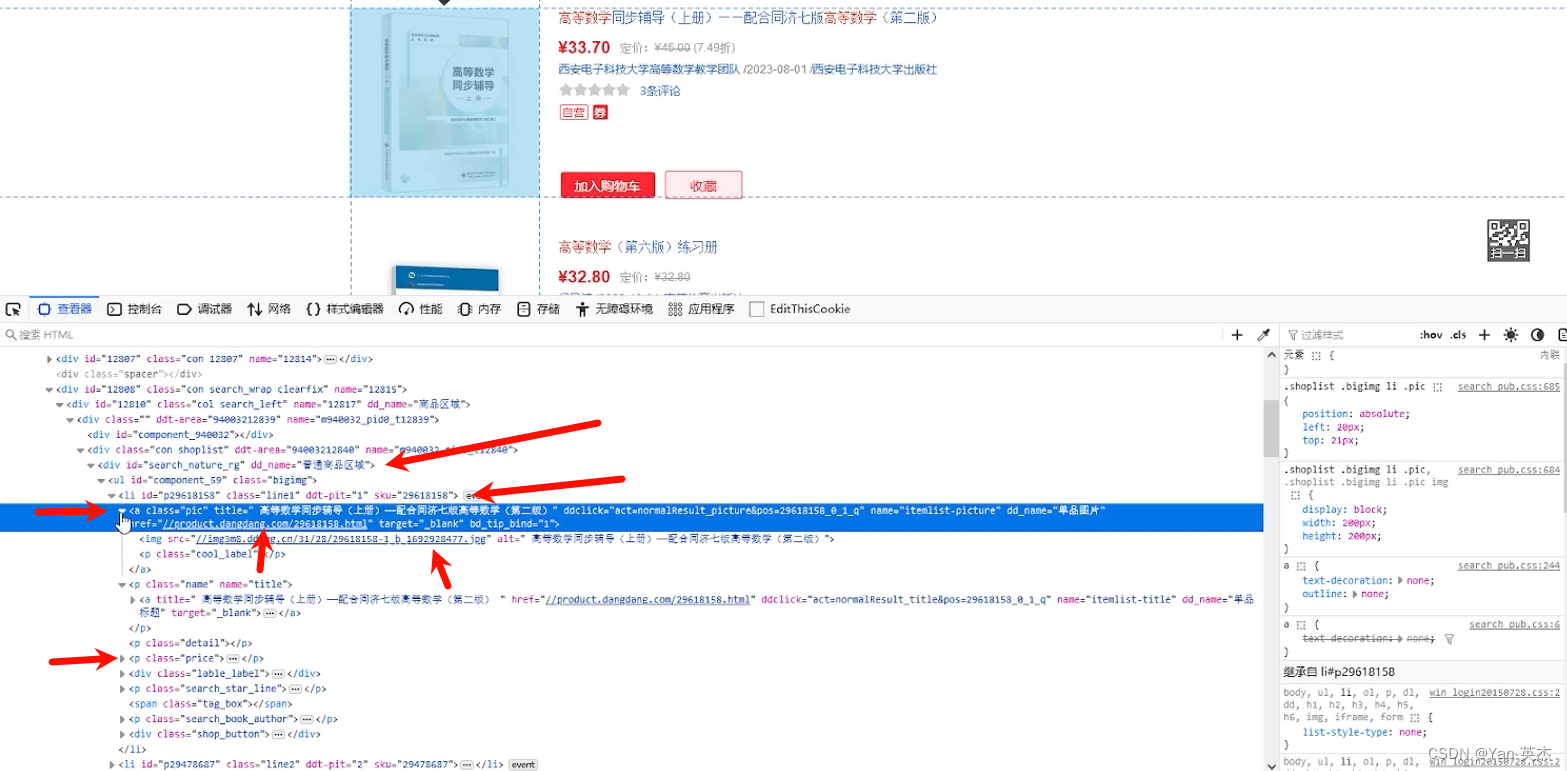
本次爬取的目标是某知名购书平台,抓取内容是:标题、链接、价格、定价、图片链接。为了防止被识别为爬虫,首先我们先要获取登录用户的cookie。登录状态下按f12,选择网络,任选其中一个流量,在请求头中找到cookie并复制。
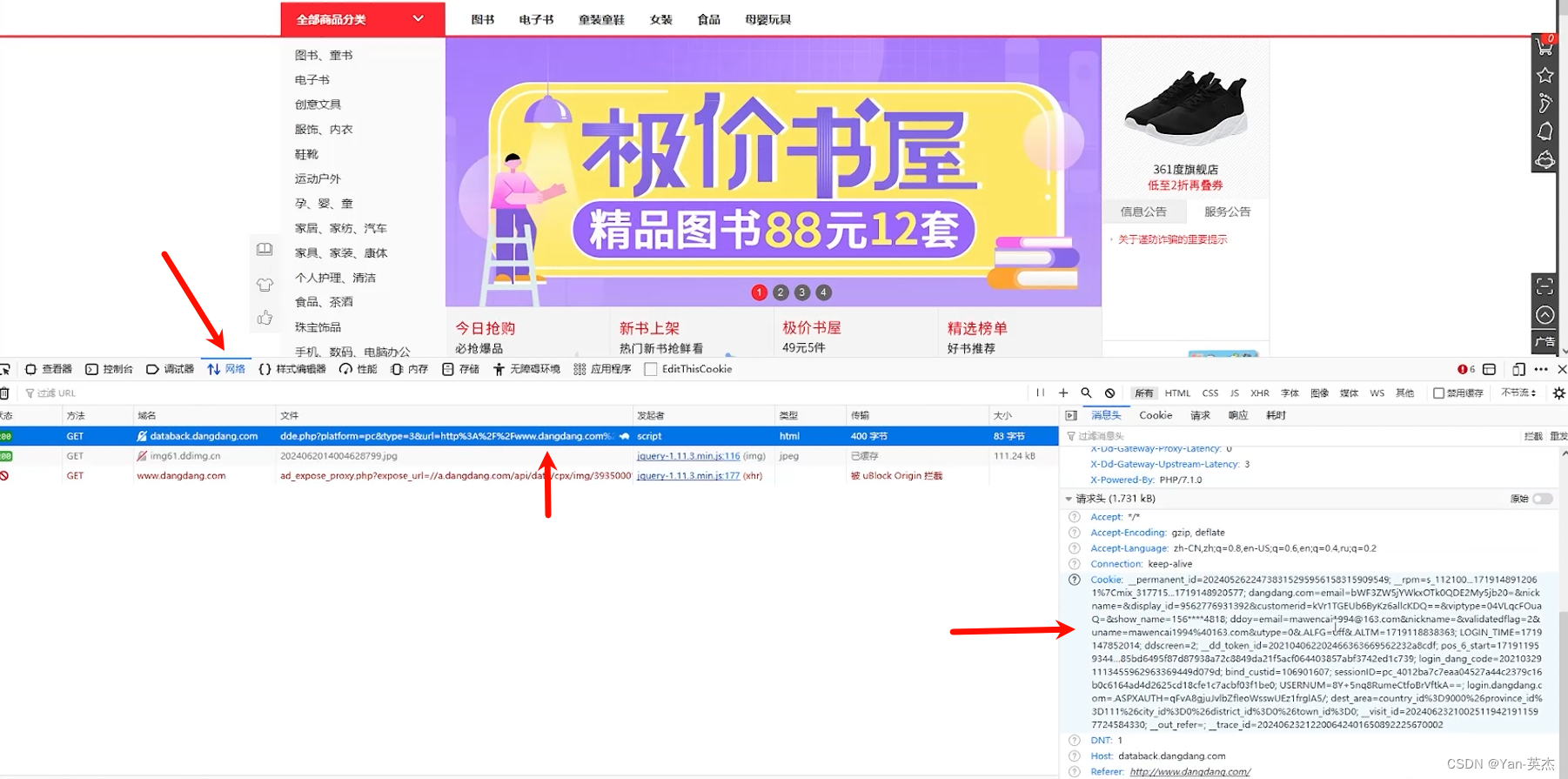
接下来,我们需要分析一下搜索请求的构建。可以看到我们搜索高等数学的时候,请求通过url构建。url中的key值代表搜索内容,act代表动作,page_index代表页码。
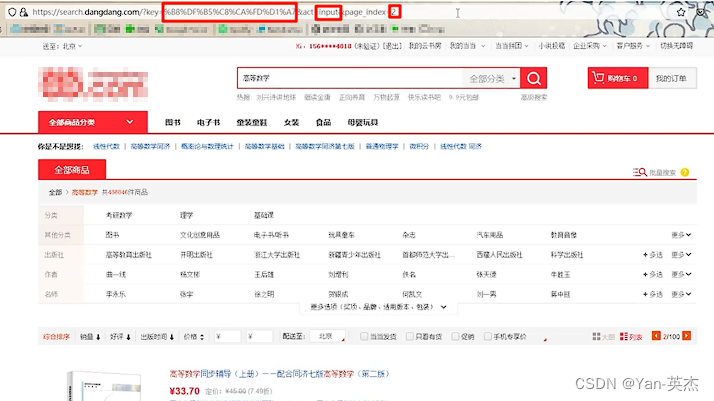
最后我们需要确定商品元素在页面中的结构。可以看到所有商品位于一个ul中,每个商品部对应一个li标签,都有对应的class标记。其中标题位于p标签的title属性,链接位于href标签,图片链接在下层的img标签中,价钱位于另一个p标签中。之后我们将用xpath定位这些标签。
获取代理
数据获取工具![]() https://www.bright.cn/proxy-types?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_yingjie
https://www.bright.cn/proxy-types?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_yingjie
为了进一步隐藏爬虫身份,我们需要使用代理来隐藏真实的IP地址。这里我们选择亮数据作为代理服务商。选择代理服务商主要关注点在稳定性、ip区域多样性和价钱上。
亮数据的IP代理网络覆盖全球195个国家,拥有超过7200万个IP地址,确保用户可以进行任意城市定位,并且每日更新上百万IP,保证了数据采集的广泛性和实时性。公司提供的代理IP网络类型包括动态住宅、静态住宅、移动和机房,全方位满足用户的不同需求。在全球范围内,亮数据拥有超过2600个代理服务器,构建了一个高速稳定的智能交通网络,确保了99.99%的稳定运行时间,即使在网络高峰期间也能保持服务的稳定性。此外,亮数据所有服务都支持随时暂停,并且计费方式灵活多样。
首先我们需要注册并登录亮数据。之后来到用户控制面板,添加代理机房。
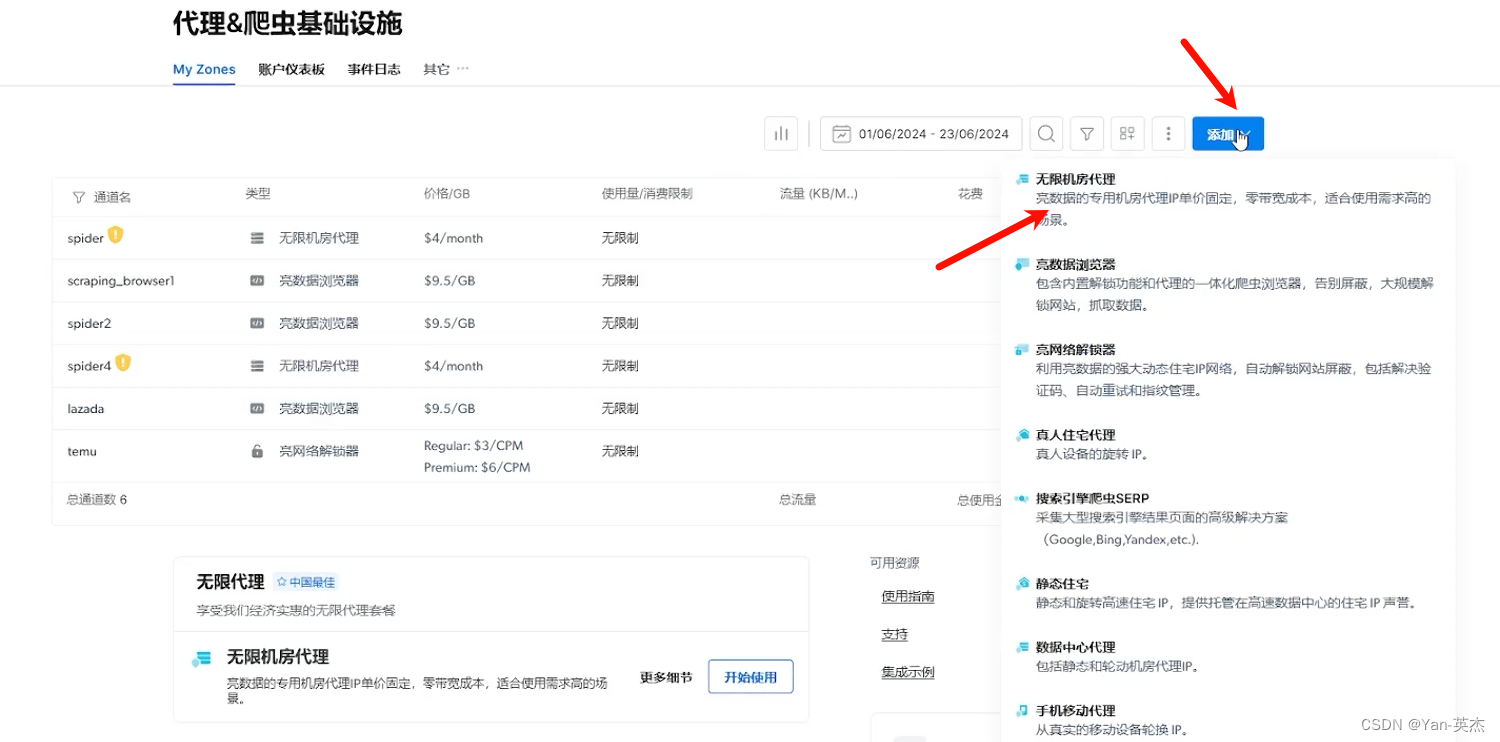
这里需要我们配置代理的名字和ip区域,其他选项保持默认。
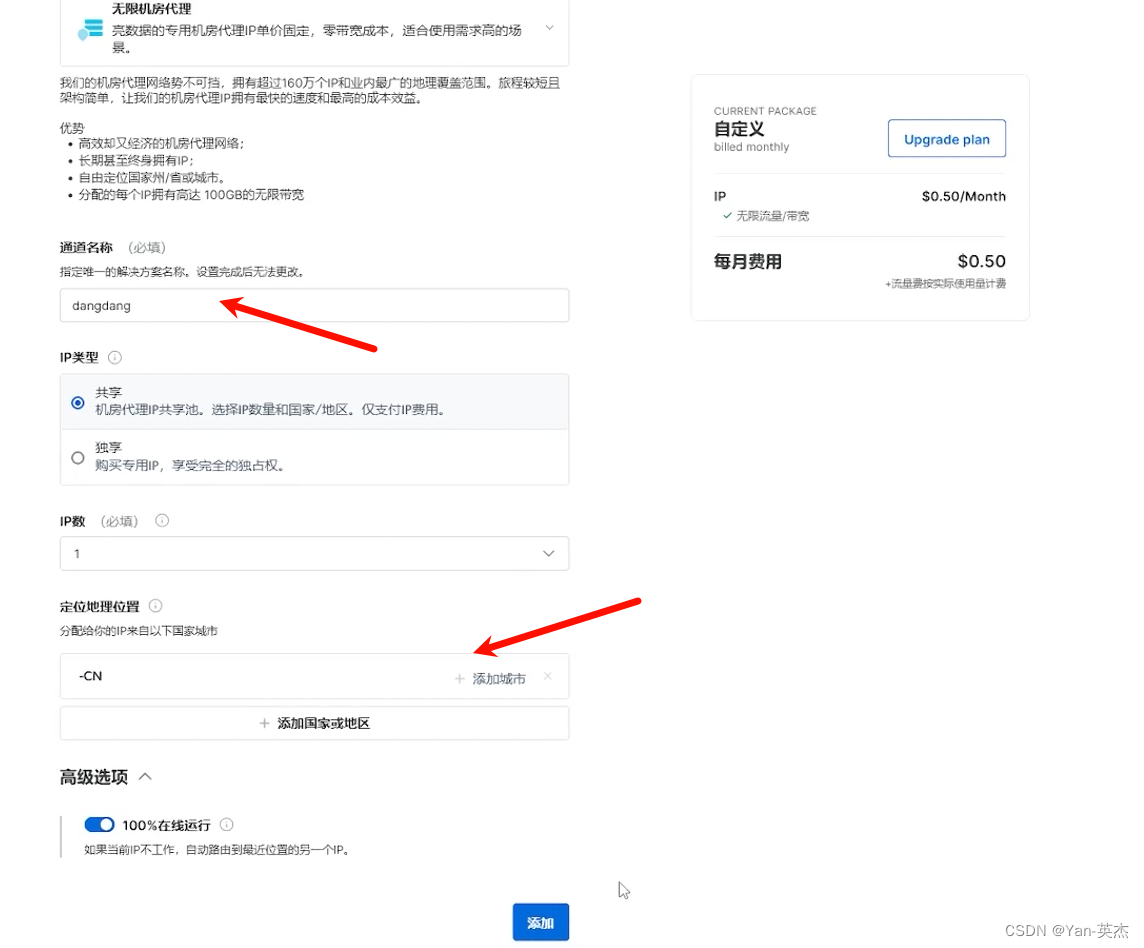
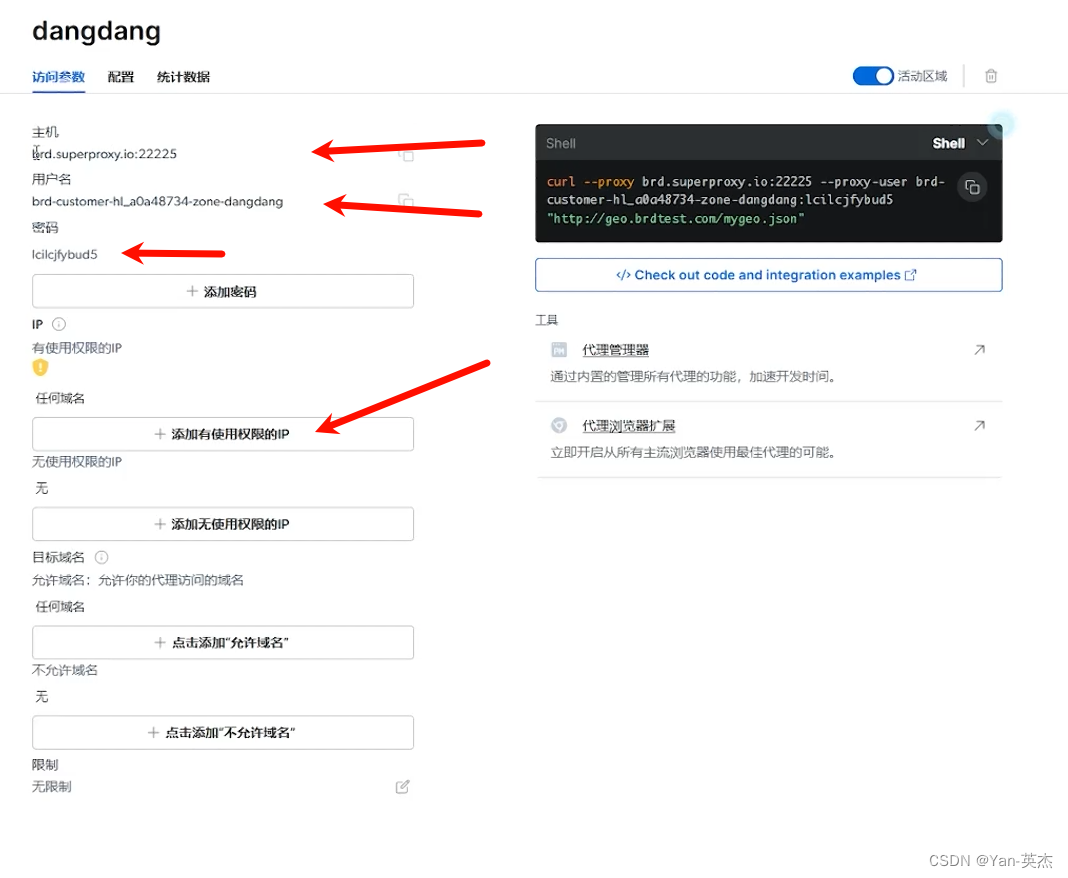
之后需要将我们本机ip添加到白名单,并记录下来主机号、账户名和密码。
编写程序
首先我们要编写get_ip函数从亮数据服务器获取代理ip:先定义代理服务器的主机、用户名和密码。然后使用这些信息构建了一个代理URL。最后发送HTTP请求到http://lumtest.com/myip.json获取当前的代理IP地址。
def get_ip():
host = '' # 主机
user_name = '' # 用户名
password = '' # 密码
proxy_url = f'http://{user_name}:{password}@{host}' # 将上面三个参数拼接为专属代理IP获取网址
proxies = {
'http': proxy_url,
'https': proxy_url
}
url = "http://lumtest.com/myip.json" # 默认获取的接口(不用修改)
response = requests.get(url, proxies=proxies, timeout=10).text # 发送请求获取IP
# print('代理IP详情信息:',response)
response_dict = eval(response) # 将字符串转为字典,方便我们提取代理IP
ip = response_dict['ip']
# print('IP:',ip)
return ip
之后需要我们定义get_html_str函数,来向电商网站发送搜索请求:先定义请求头,模拟浏览器访问,其中包含了一些cookie信息。调用get_ip函数获取代理IP,并设置到请求中。最后发送HTTP请求到指定的URL,并返回网页源码。
def get_html_str(url):
"""发送请求,获取网页源码"""
# 请求头模拟浏览器(注意这里一定添加自己已经登录的cookie才可以)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'cookie': ''
}
# 添加代理IP
proxies = get_ip()
# proxies = {}
# 添加请求头和代理IP发送请求
response = requests.get(url, headers=headers, proxies=proxies)
# 获取网页源码
html_str = response.text
# 返回网页源码
return html_str
写下来要定义get_data函数,来解析网页中的元素,找到目标文本:首先接收网页源码、页码和数据列表作为参数。然后使用lxml.etree解析网页源码,提取商品信息,包括标题、价格、定价、商品链接和图片链接。最后将提取的数据添加到数据列表中。
def get_data(html_str, page, data_list):
"""提取数据写入列表"""
# 将html字符串转换为etree对象方便后面使用xpath进行解析
html_data = etree.HTML(html_str)
# 利用xpath取到所有的li标签
li_list = html_data.xpath('//div[@dd_name="普通商品区域"]/ul/li')
# 打印一下li标签个数
# print(len(li_list))
# 遍历li_list列表取到某一个商品的对象标签
for li in li_list:
# 标题
title = li.xpath('.//a[@class="pic"]/@title')
title = ''.join(title)
# 商品链接
goods_url = 'https:' + li.xpath('.//a[@class="pic"]/@href')[0]
# 价格
price = li.xpath('.//p[@class="price"]/span[@class="price_n"]/text()')[0]
print(price)
# 定价
pre_price = li.xpath('.//p[@class="price"]/span[@class="price_r"]/text()')[0]
# 图片链接
img_url = 'https:' + li.xpath('.//a[@class="pic"]/img/@src')[0]
print({'页码': page, '标题': title, '价格': price, '定价': pre_price, '商品链接': goods_url,
'图片链接': img_url})
data_list.append(
{'页码': page, '标题': title, '价格': price, '定价': pre_price, '商品链接': goods_url,
'图片链接': img_url})
接下来定义to_excel函数,将获取到的结果保存为excel文件:首先将数据列表转换为pandas的DataFrame对象。然后删除DataFrame中的重复数据。最后将DataFrame保存为Excel文件。
def to_excel(data_list):
"""写入Excel"""
df = pd.DataFrame(data_list)
df.drop_duplicates() # 删除重复数据
df.to_excel('当当采集数据集.xlsx')
最后定义一个main函数方便调节参数、控制流程:首先设置爬取的关键词和页数。然后初始化一个空的数据列表。之后循环遍历每一页,调用get_html_str和get_data函数获取数据。最后调用to_excel函数将数据写入Excel文件。
def main():
# 1. 设置爬取的关键词和页数
keyword = '手机'
page_num = 1 # 爬取的页数
data_list = [] # 空列表用于存储数据
for page in range(1, page_num + 1):
url = f'https://search.dangdang.com/?key={keyword}&act=input&page_index={page}'
print(url)
# 2. 获取指定页的网页源码
html_str = get_html_str(url)
# print(html_str)
# 3. 提取数据
get_data(html_str, page, data_list)
time.sleep(1)
# 4. 写入Excel
to_excel(data_list)
完整代码如下:
import pandas as pd # pandas,用于写入Excel文件
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import time # 防止爬取过快可以睡眠一秒
def get_ip():
host = '' # 主机
user_name = '' # 用户名
password = '' # 密码
proxy_url = f'http://{user_name}:{password}@{host}' # 将上面三个参数拼接为专属代理IP获取网址
proxies = {
'http': proxy_url,
'https': proxy_url
}
url = "http://lumtest.com/myip.json" # 默认获取的接口(不用修改)
response = requests.get(url, proxies=proxies, timeout=10).text # 发送请求获取IP
# print('代理IP详情信息:',response)
response_dict = eval(response) # 将字符串转为字典,方便我们提取代理IP
ip = response_dict['ip']
# print('IP:',ip)
return ip
def get_html_str(url):
"""发送请求,获取网页源码"""
# 请求头模拟浏览器(注意这里一定添加自己已经登录的cookie才可以)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'cookie': ''
}
# 添加代理IP
proxies = get_ip()
# proxies = {}
# 添加请求头和代理IP发送请求
response = requests.get(url, headers=headers, proxies=proxies)
# 获取网页源码
html_str = response.text
# 返回网页源码
return html_str
def get_data(html_str, page, data_list):
"""提取数据写入列表"""
# 将html字符串转换为etree对象方便后面使用xpath进行解析
html_data = etree.HTML(html_str)
# 利用xpath取到所有的li标签
li_list = html_data.xpath('//div[@dd_name="普通商品区域"]/ul/li')
# 打印一下li标签个数
# print(len(li_list))
# 遍历li_list列表取到某一个商品的对象标签
for li in li_list:
# 标题
title = li.xpath('.//a[@class="pic"]/@title')
title = ''.join(title)
# 商品链接
goods_url = 'https:' + li.xpath('.//a[@class="pic"]/@href')[0]
# 价格
price = li.xpath('.//p[@class="price"]/span[@class="price_n"]/text()')[0]
print(price)
# 定价
pre_price = li.xpath('.//p[@class="price"]/span[@class="price_r"]/text()')[0]
# 图片链接
img_url = 'https:' + li.xpath('.//a[@class="pic"]/img/@src')[0]
print({'页码': page, '标题': title, '价格': price, '定价': pre_price, '商品链接': goods_url,
'图片链接': img_url})
data_list.append(
{'页码': page, '标题': title, '价格': price, '定价': pre_price, '商品链接': goods_url,
'图片链接': img_url})
def to_excel(data_list):
"""写入Excel"""
df = pd.DataFrame(data_list)
df.drop_duplicates() # 删除重复数据
df.to_excel('当当采集数据集.xlsx')
def main():
# 1. 设置爬取的关键词和页数
keyword = '手机'
page_num = 1 # 爬取的页数
data_list = [] # 空列表用于存储数据
for page in range(1, page_num + 1):
url = f'https://search.dangdang.com/?key={keyword}&act=input&page_index={page}'
print(url)
# 2. 获取指定页的网页源码
html_str = get_html_str(url)
# print(html_str)
# 3. 提取数据
get_data(html_str, page, data_list)
time.sleep(1)
# 4. 写入Excel
to_excel(data_list)
if __name__ == '__main__':
main()
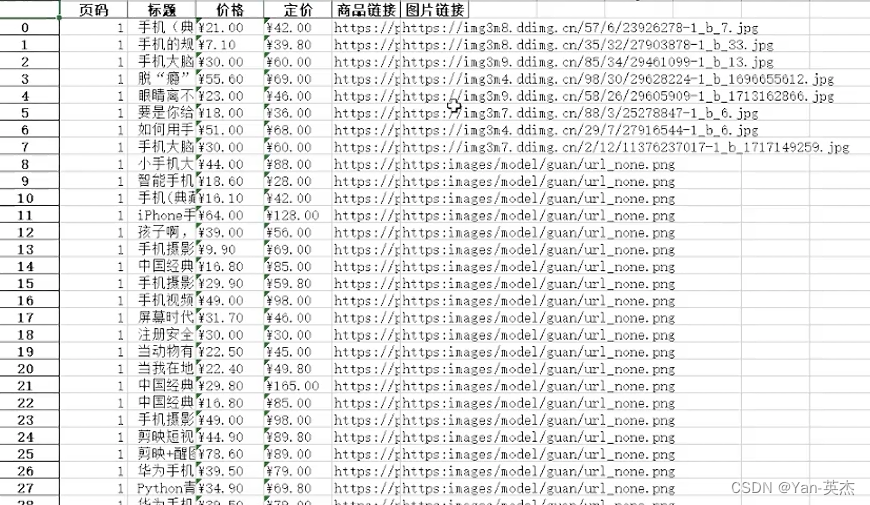
将cookie、主机名、账号和密码跳入对应位置即可运行。运行结果如下:

打开excel文档,即可看到抓取到的数据。
总结
通过上面的实战,我们可以看到代理服务可以大大提高爬虫的匿名性和效率。亮数据家的代理可以满足这两点需求。
对开发者而言,亮数据代理以其简单易用的特性,大幅降低了技术门槛。 开发者可以快速上手,无需深入了解代理服务的底层技术细节,即可实现高效的数据抓取。这不仅加快了开发进程,也使得开发者能够将更多精力投入到数据分析和业务逻辑的构建上。
对于采购者,亮数据代理提供的价格实惠和套餐灵活,满足了不同规模和需求的采购预算。 用户可以根据自己的实际需求选择合适的套餐,无论是初创企业还是大型机构,都能找到符合自身预算的解决方案。对项目经理来说,亮数据代理的高效数据质量保障,确保了爬取过程的稳定性和数据的准确性。 这不仅提升了项目的整体执行效率,也保障了数据分析结果的可靠性,为决策提供了坚实的数据支撑。
对于企业老板,安全合规是他们最关心的问题之一, 亮数据代理严格遵守数据采集的法律法规,确保了企业在使用过程中的合规性,降低了潜在的法律风险。
综上所述,亮数据代理产品以其多维度的优势,为电商平台爬虫的实现提供了强有力的支持。无论是技术实现的便捷性,还是成本控制的灵活性,或是数据质量的高效性,以及整体操作的安全性,亮数据代理都是企业和个人在数据采集领域的理想选择。随着技术的不断进步和市场需求的日益增长,我们可以预见,代理服务将在电商数据采集领域扮演越来越重要的角色